Fine-tune LLM using Reinforcement Learning from Human Feedback (RLHF)
Introduction
In this blog, I have discussed how to fine-tune LLM to generate less toxic content with Meta AI’s hate speech reward model. The reward model is a binary classifier that predicts either “not hate” or “hate” for the given text. I have used Proximal Policy Optimization (PPO) to fine-tune and reduce the model’s toxicity.
What is reinforcement learning and how does it work ?
Reinforcement Learning (RL) - an agent learns to make decisions related to a specific goal by taking actions in an environment, with the objective of maximising rewards.
In this framework, the agent continually learns from its experiences by taking actions, observing the resulting changes in the environment, and receiving rewards or penalties, based on the outcomes of its actions. By iterating through this process, the agent gradually refines its strategy or policy to make better decisions and increase its chances of success.
RLHF - Reinforcement Learning with Human Feedback
Using reinforcement learning to finetune the LLM with human feedback data, resulting in a model that is better aligned with human preferences. This is done to prevent the model from giving toxic replies, harmful replies etc. The resulting model is called Human aligned LLM.
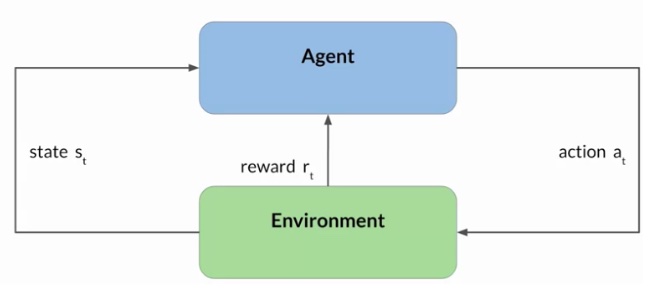
Image source : Generative AI with LLMs by Courseera
Load the model and dataset
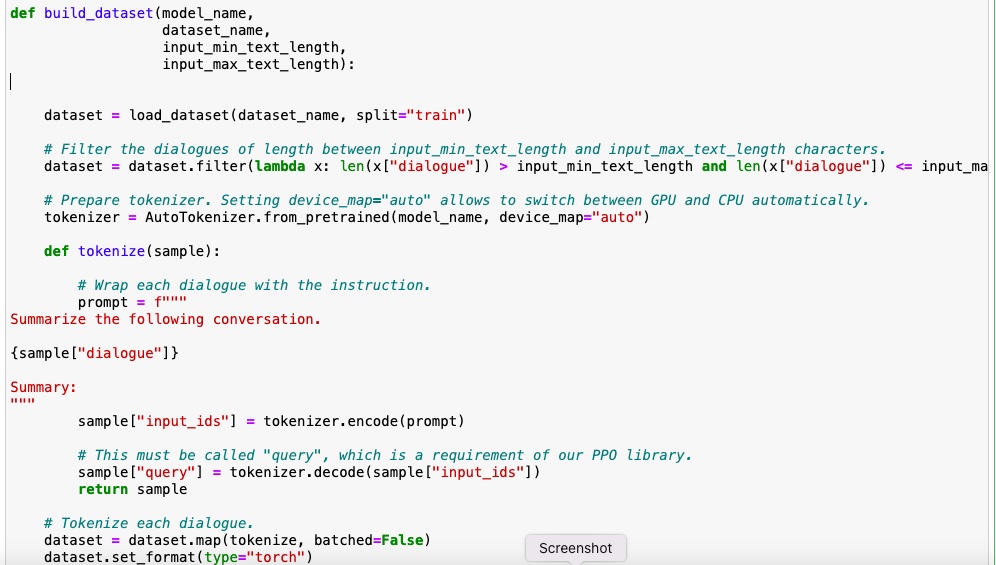
First step is to install and import all the necessary libraries such as transformers, datasets, torch etc. Then load the Flan T5 model and the dataset.
The next step will be to preprocess the dataset. I have filtered the dialogues of a particular length (just to make those examples long enough and, at the same time, easy to read). Then wrap each dialogue with the instruction and tokenize the prompts. Save the token ids in the field input_ids and decoded version of the prompts in the field query.
I have used the fine tuned PEFT model from the previous experiment ( blog post). The same adapter is used with 1.4% of trainable parameters.
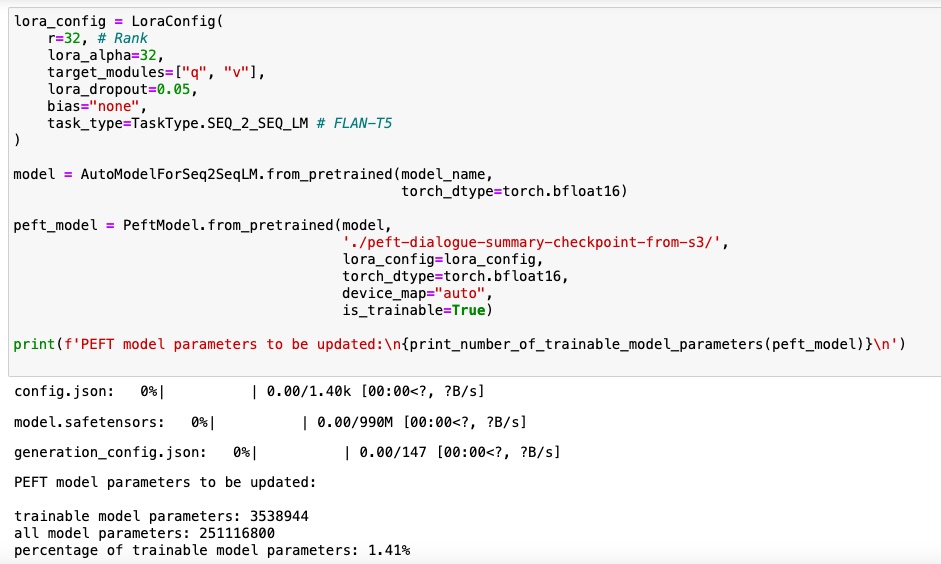
Now create a frozen copy of the PPO which will not be fine-tuned - a reference model. The reference model will represent the LLM before detoxification. None of the parameters of the reference model will be updated during PPO training. This is on purpose.

Next step is to fine tune the LLM to detoxify the output of the model. A human labeler can be used to give feedback on the toxicity level of the output. But this can be an expensive process to hire someone to do this. so we can use the reward model for this task. This Reward model can be used to perform sentiment analysis i.e classify the output into two classes (nothate and hate) and give a higher/lower reward based on the output. Meta AI’s RoBERTa-based hate speech model (facebook/roberta-hate-speech-dynabench-r4-target · Hugging Face) is used here as a reward model.
The configuration parameters are set up and the model is loaded to perform fine tuning. Also the reference model i.e the frozen version of the original model is also used .
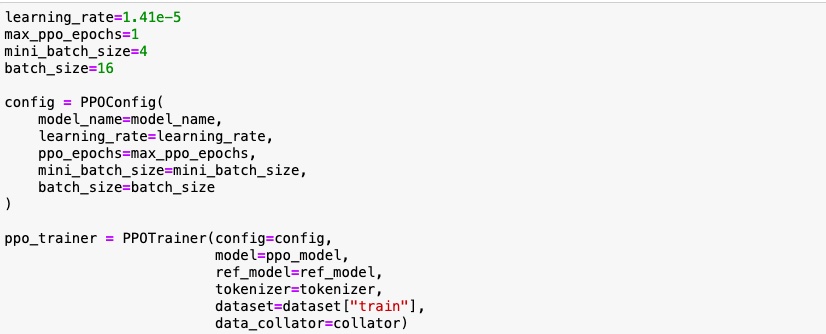
These are the fine-tuning main steps:
- Get the output from the LLM (PEFT model).
- The sentiments for query/responses are classified using hate speech RoBERTa model.
- Optimize policy with PPO using the (query, response, reward) triplet.
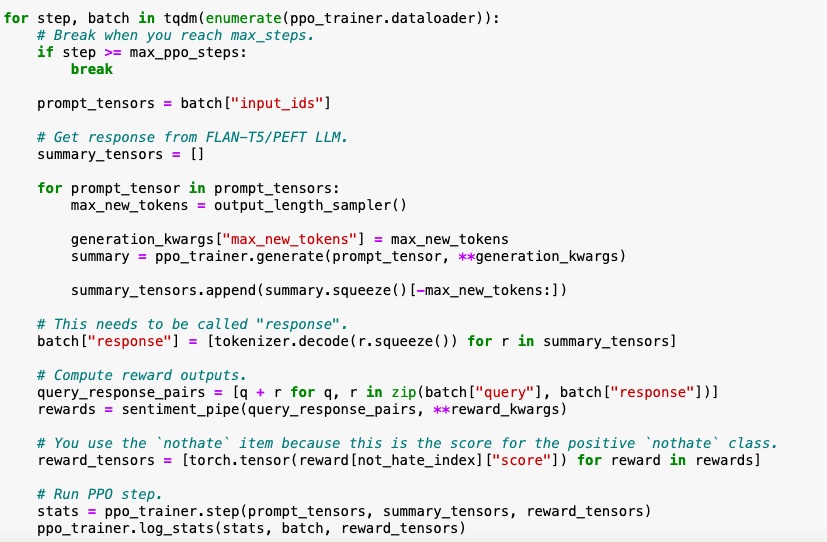
I have evaluated the fine-tuned model in the below section. I have compared it against the reference model using the reward score.

Conclusion :
RLHF Is that useful method in case of applications such as - chatbots or question answering type applications etc. It is not useful in case of applications such as performing classification or regression type of problem
The full code can be found here - colab notebook
Reference :
Generative AI with LLMs , Deeplearning.AI