Full fine-tuning & PEFT techniques with LLMs
Dialogue summarization using full fine-tuning & PEFT techniques with LLMs
This is my first blog. (Yay!) I’m jumping on the bandwagon to kickstart a series of blog articles all about ML and share my learnings with you. Not only this is my first blog but also I have created my first meme (below) :)

Let’s get started. In this blog I have explained the process of full fine-tuning and using PEFT techniques on LLMs. I have used FLAN-T5 model to perform dialogue summarization. I have evaluated the performance and compared the results using both full fine-tuning and PEFT.
The dataset used is from hugging face called DialogSum https://huggingface.co/datasets/knkarthick/dialogsum
First step, Install and import all the necessary libraries such as transformers, datasets, torch etc. Then load the Flan T5 model and create an instance using AutoModelForSeq2SeqLM and then download the tokenizer using AutoTokenizer.
Full fine-tuning
Preprocess the dataset
LLM requires the data to be in a certain format. So the prompt and dialogue are added in below format.
1
2
3
4
5
Summarize the following conversation.
{..... conversation...}
Summary :
The below function adds a start prompt and end prompt based on the above format. Using the tokenizer, the input_ids and labels are obtained.
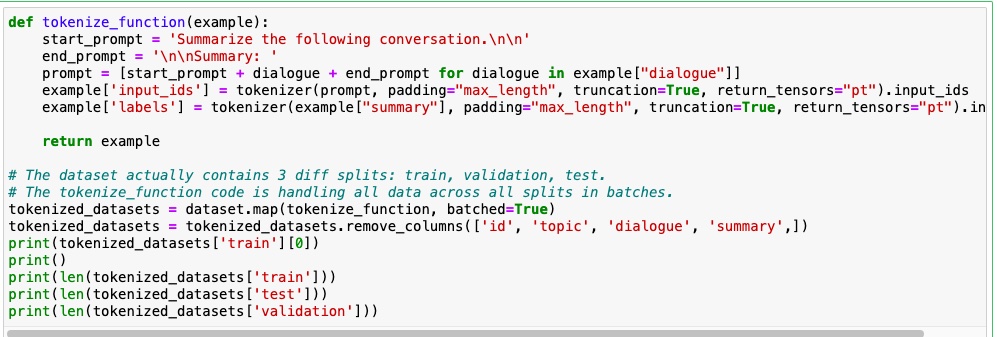
Fine-tuning process
Using the hugging face trainer class I have fine tuned the model. it requires certain arguments to be passed such as the original model, training arguments, training data set and the evaluation data set. Training arguments involve a number of parameters such as learning rate, epochs etc. The value for these parameters are set based upon the need of the project. More details about the Trainer class can be found here https://huggingface.co/docs/transformers/en/main_classes/trainer

The training steps takes time. After its completion the model performance is evaluated. I have compared the result from the original model vs the fine-tuned model for a sample dialogue. This gives an eye-to-eye comparison of the result.
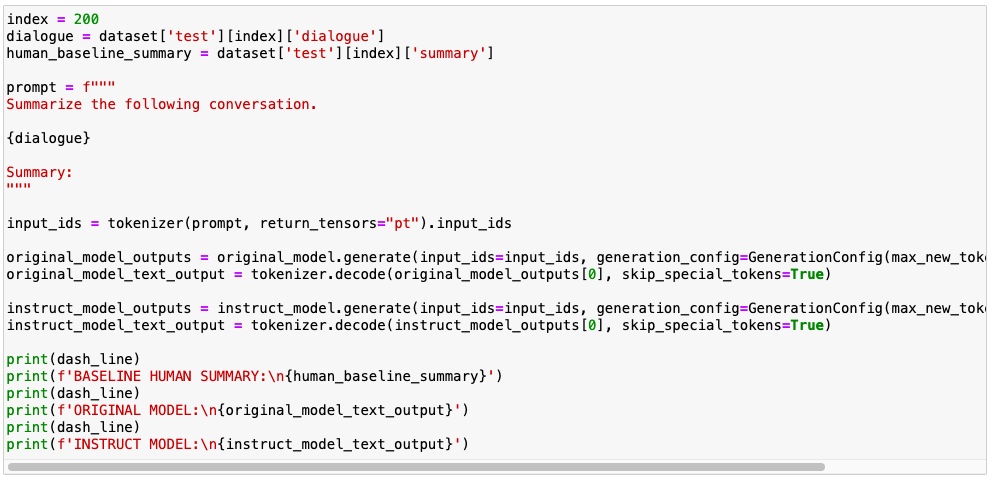
Evaluation - using ROUGE metrics
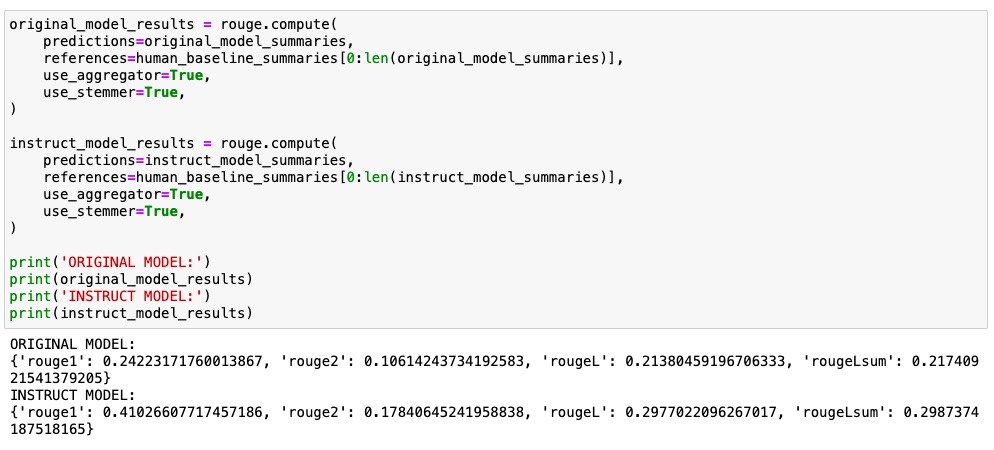
I have used ROGUE metrics to evaluate the performance of the model. It compares the model generated summary to the baseline human summary and calculates a metric score. This helps to evaluate the performance of the original model and the fine tune model. More details about rouge metrics can be found here https://huggingface.co/spaces/evaluate-metric/rouge
Rouge1 and rouge2 are unigram based scoring and bigram based scoring respectively. Whereas rougeL means longest subsequence based scoring.
We can see that rouge metrics scores for instruct model is comparatively higher than original model scores.
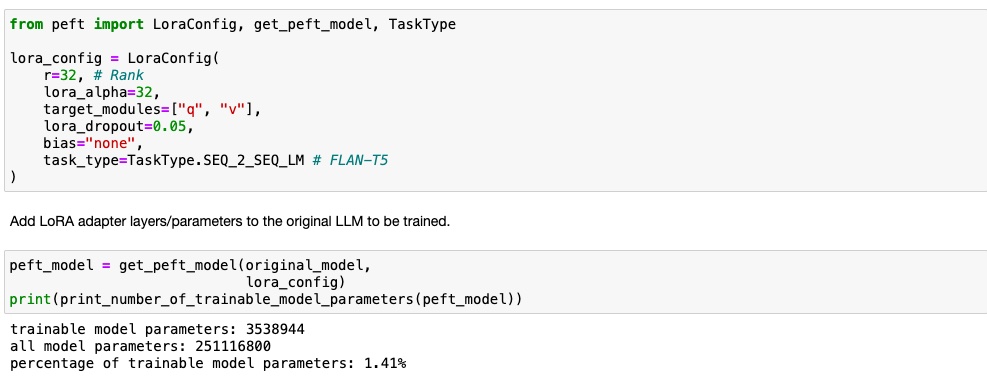
PEFT - Parameter Efficient Fine-tuning
PEFT is a popular and most widely used technique for fine-tuning LLM. It includes types such as LoRA, prompt tuning, IA3 etc. Among these the most commonly used technique is LoRA. It introduces low rank decomposition matrices that will be learnt during fine tuning. So the original model’s weights are frozen and only the smaller matrices are updated. Because of this, the computational resources needed for training are greatly reduced. Also the training time, cost, memory usage etc are reduced.
LoRA adapter is first set up with the following configuration. This is added to the original LLM during the training process. The original LLM weights are frozen and the LoRA adapter layers are trained.
1
2
3
4
5
R- is the rank. Smaller value gives small matrix update
Lora_alpha - is a scaling parameter that controls the scaling of the matrices
Target_modules - the layers in attention block where LoRA update will apply
Lora_dropout - is a regularization technique where random parameters are dropped out to avoid overfitting
Task_type - refer to below screenshot. The list of different task types and its corresponding usage is given (source : hugging face library https://github.com/huggingface/peft/blob/v0.8.2/src/peft/utils/peft_types.py#L68-L73 )

Training PEFT adapter using Trainer class. Once training is completed, save the model.
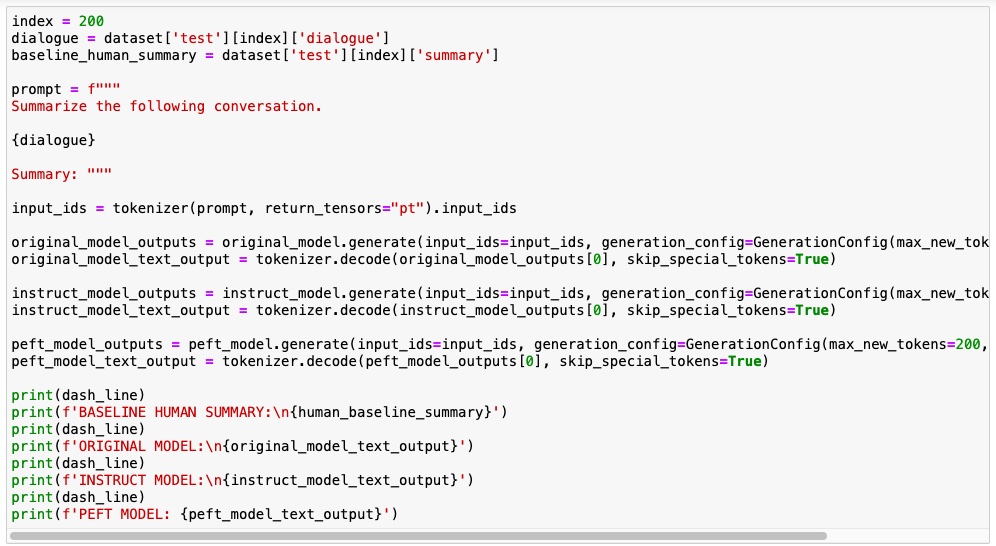
Evaluate the performance of the model using a dialogue from the dataset. I have compared the results of the output of the original model, full fine tuned model and peft model.
Evaluation - using ROUGE metrics
Here rouge metrics scores are calculated and a comparison of the performance evaluation is done for original model, fully fine tuned model and peft model.
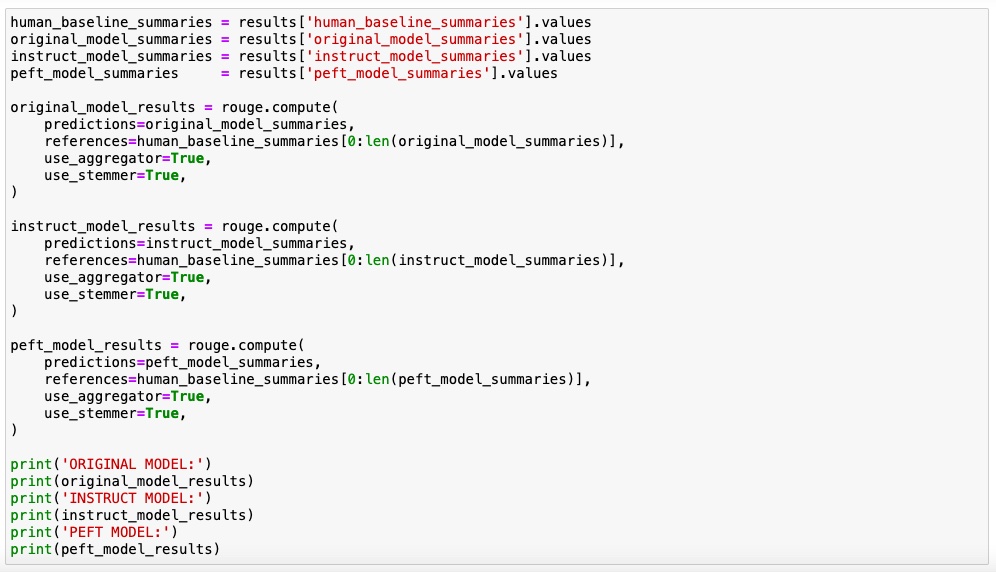
Even though peft model scores are slightly lower than full fine tuned model scores, the benefits of using peft outweighs the lower scores.
Conclusion :
I have explained how to perform full fine tuning using LLMs and also have explained the steps involved to perform PEFT with LLMs. The results of the ROUGE metrics show that even though PEFT has a slightly lower performance, the benefits of using PEFT outweighs full fine tuning because of usage of less computational resources and time. The full colab can be found here colab notebook
Reference :
Generative AI with LLMs , Deeplearning.AI Hugging face, PEFT, https://huggingface.co/docs/peft/en/index