Faster LLM fine-tuning with Unsloth and using QLORA technique for memory reduction
Introduction
In this article I have explained how to fine-tune Llama 3.1 8B model using QLoRA technique. In the previous article I explained about using full-tuning and LoRA to fine-tune the model and compared the pros and cons of using them. Here I’m going to use QLoRA technique along with Unsloth for 2x faster inference.
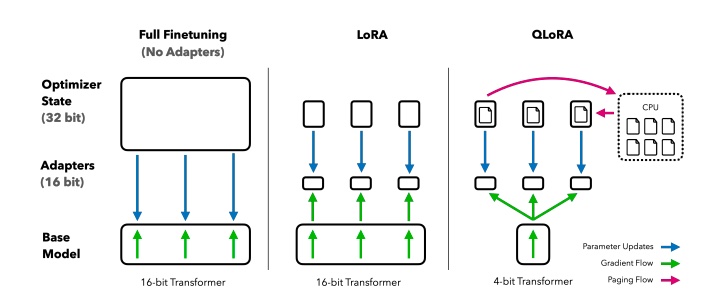
Image source: https://arxiv.org/pdf/2305.14314
What is Full fine-tuning ?
Instruction fine-tuning, where all of the model’s weights are updated, is known as full fine-tuning. The process results in a new version of the model with updated weights. But it requires a lot of memory, cost and compute power.
There are some disadvantages to this fine tuning called catastrophic forgetting. It is because the full fine-tuning process modifies the weights of the original LLM. While this leads to great performance on the single fine-tuning task, it can degrade performance on other tasks
To avoid catastrophic forgetting do :
- Fine tune on multiple tasks rather than just one
- Do Parameter efficient fine tuning (PEFT) instead of full fine tuning
- PEFT preserves the weights of the original LLM & most of the pre-trained weights are left unchanged
It is a destructive method as it makes the model forget previously learned things.
LoRA
Instead of modifying all the parameters of a pre-trained model, LoRA adds low-rank matrices to specific layers (e.g., attention layers) in the network. These matrices are trained while the original model parameters are kept frozen. It saves a lot of time, money, resources needed and huge memory reduction. Since they train only a small percent of the parameters, it needs very less VRAM. These lora adapters can be fine tuned on various tasks and can be swapped and used as needed.
QLoRA
This technique is an extension of LoRA, where quantization is applied on the low rank matrices. So it achieves 4x memory reduction compared to LoRA. Because of this it has comparatively lower accuracy than LoRA.
Unsloth
I chose Unsloth for fine-tuning because Unsloth makes fine-tuning of LLMs 2.2x faster and uses 80% less VRAM! More info here https://unsloth.ai As per the recent update, Unsloth now supports fine-tuning of LLMs with very long context windows, up to 228K https://unsloth.ai/blog/long-context. Also it can be used with most model architectures and they support multi-GPU as well. Making it one of the best choices to fine-tune LLM. Hence I experimented fine-tuning Llama 3.1 using Unsloth. Install all the necessary libraries and import them. As I’m going to explore QLoRA technique I have used the pre-quantized unsloth/Meta-Llama-3.1-8B-bnb-4bit . This 4-bit precision version is much smaller (5.4 GB) and faster to download than the original model (16 GB).
Image source: https://arxiv.org/pdf/2305.14314
First step is to install and import all the necessary libraries. Then download the model and tokenizer.
Understanding the different parameters
max_seq_length - The maximum sequence length of the inputs.
load_in_4bit - This flag is used to enable 4-bit quantization, its default value is False
dtype - it stands for data type. It is used to specify the precision or type of numerical data used for computations (such as the model’s weights). Ex: float32 - means 32-bit floating point numbers, float16 - means 16-bit floating point numbers, used to reduce memory usage and accelerate computation
Here I have set the max_seq_length to 2048. We can set it to any higher number as Unsloth now supports upto 228k, but Llama has a context length of 128k.

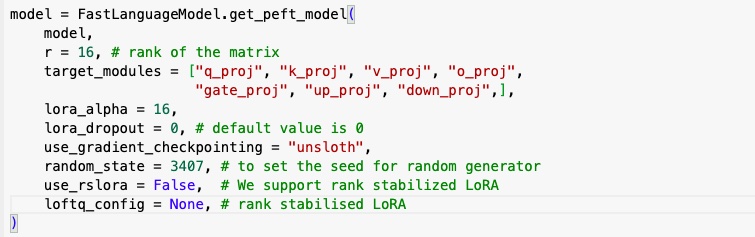
Next step is to perform parameter efficient fine tuning by using the following parameters to get the LoRA adapters.
Understanding the different parameters
r - is the rank.It is dimensionality of the low-rank matrices that are used to approximate the model’s weight updates. A higher value of r allows the model to learn more complex transformations but increases the number of parameters. It ranges from 8 to 256.
target_modules - It is the target modules where the LoRA update matrices are applied. For transformer-based models, typical target modules include query (q), key (k), and value (v) projection layers in the attention mechanism. It can also be linear output layers, feed forward layers etc.
lora_alpha - is a scaling parameter that controls the scaling of the matrices. Alpha scales the learned weights. According to the LoRA paper, it is generally advised to fix Alpha—often at 16—rather than treating it as a tunable hyperparameter.
lora_dropout - It is used to function against overfitting, enhancing both model accuracy and reliability. Default value is 0. A value of 0 disables dropout, which can sometimes improve the performance of LoRA-based models.
use_gradient_checkpointing - I have used ‘unsloth’ to reduce disk space and for memory reduction. This parameter is used to save memory by checkpointing activations, so it is able to allow larger batch sizes and longer context lengths during training. “unsloth” is used to reduce VRAM usage and have larger batch sizes.
random_state - Used for random number generation. Random_state is used to set the seed for the random generator inorder to make sure that the results that we get can be reproduced every time. When we use train_test_split , the training data and testing data are selected randomly. We don’t have control over that. But using this feature we can control that now. For example, we have numbers from 1 to 10. If we want to split this randomly into 2, we might get 1,2,5,6,3 and 4,7,8,9,10. Next time we split we will get a completely different set.
But by setting the random state to 0, 1 or any other number, we would get the same random numbers generated. For instance if for random_state=1, the generated random numbers are 4,7,8,9,10 and 1,2,5,6,3, then everyone who picks two random numbers set using random_state=1 will get the same numbers. By this way we can make sure the train_test_split is always deterministic i.e same each time.
use_rslora - stands for rank stabilized LoRA, it alters the scaling factor of LoRA adapters to be proportional to 1/√r instead of 1/r. It is used to stabilise learning in case of higher rank. Refer to this paper for more info https://arxiv.org/abs/2312.03732
I have used yahma/alpaca-cleaned dataset for fine-tuning. It has 51k rows of data. This has to be converted to Instruction, input, output format. The below function takes care of converting the dataset to the required format. It is important to add the EOS_TOKEN to the tokenized output. Otherwise you’ll get infinite generations. EOS stands for end-of-sequence. It is a special token used to signify the end of a sequence. It is important to use that in models that generate text, as it indicates where the model should consider the sequence to be complete.

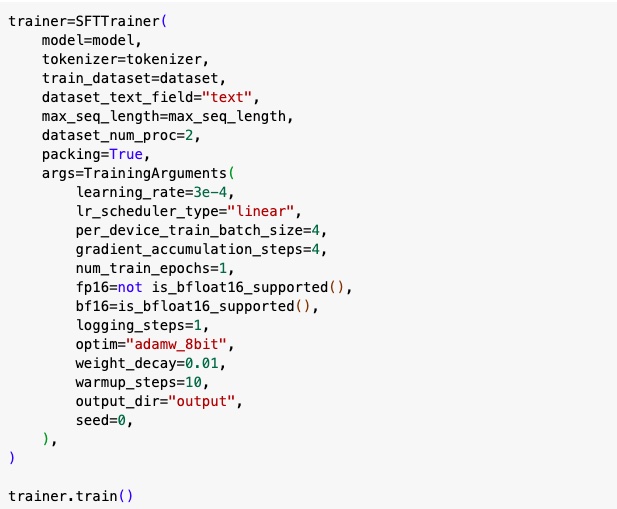
Using SFTTrainer I have trained the model to develop the peft adapter.
Understanding the different parameters :
learning_rate - This parameter is used to measure the step size during each iteration to minimize the loss function i.e the rate at which the model updates the parameters. If it’s too low, then it will be slow and may get stuck in local minima. If it’s too high, it becomes unstable.
lr_scheduler_type - It is used to adjust the learning rate. ‘Linear’ means the learning rate linearly decreases with epochs. It is one of the most commonly used ones.
per_device_train_batch_size - it refers to the number of samples that are processed. For example, incase of image data - a batch of 2 will read, and train, two images simultaneously.
gradient_accumulation_steps - instead of updating the model parameters after processing each individual batch of training data, the gradients are accumulated over multiple batches before updating. So after it has processed ‘X’ number of batches, the accumulated gradients are used to update the model parameters. This way the amount of memory needed for training is reduced. It is used in cases, when the batch size is very large to fit into the memory.
num_train_epochs - It is the number of times the network will go through the entire training dataset
logging_steps - Logging is done every x logging_steps
optim - It is used to adjust the model parameters to minimise the loss function. AdamW 8-bit is the most used recommended optimizer
weight_decay - It is a technique used to avoid overfitting. A penalty is given to the loss function during training, which tells the model to keep its weights small. So large weights get a higher penalty.
warmup_steps - Warmup steps are just a few updates with low learning rate before / at the beginning of training. After this, you use the regular learning rate (schedule) to train your model to convergence.
seed - It is used to set the random generator inorder to make sure that the results that we get can be reproduced every time.
Now the model has been trained. I have tested it with an example, just to get an idea of how it performs. FastLanguageModel from Unsloth is used here for 2x faster inference FastLanguageModel.for_inference(model).
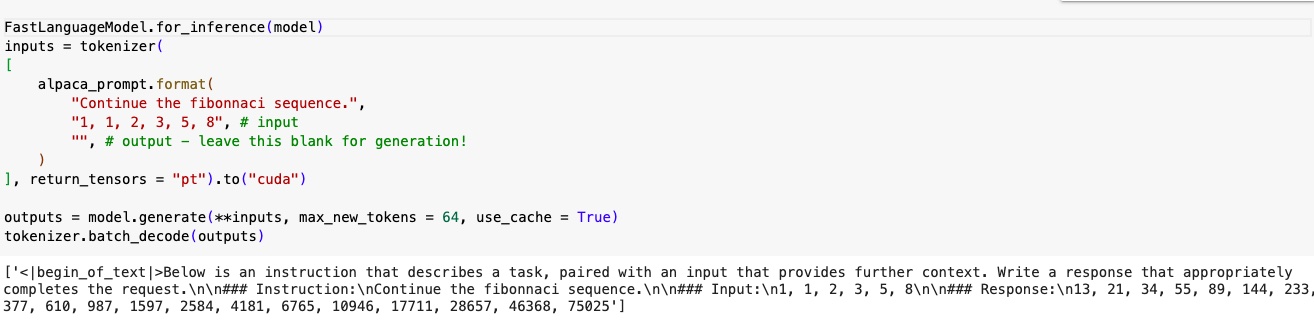
I have asked the model to continue the fibonacci sequence by giving an input - “1, 1, 2, 3, 5, 8”
It gave an output as below
13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946, 17711, 28657, 46368, 75025
I cross checked to confirm that the output is correct.
Next we have to save the model. The trained output is not the model itself, it’s the adapters that we have developed using the lora config parameters. The model can be saved either locally or can be saved in your hugging face account. To save it locally use save_pretrained() function, to save it in your hugging face account use model.push_to_hub().

Conclusion :
In this article I have provided a comprehensive explanation and comparison of the different fine-tuning techniques and how Unsloth can be leveraged for faster finetuning. The selection of a finetuning technique is based on the needs of the project and the resources you got. LoRA is a good candidate if you have access to a lot of GPU and enough space. If you have only limited GPU memory, then QLoRA can be chosen.
The full code can be found here - colab notebook
Reference :
https://www.hopsworks.ai/dictionary/gradient-accumulation